Omnis Studio and Unicode
By David Swain
Polymath Business Systems
In the spirit of the New Year, perhaps
it is time to reflect a bit on how humanity can all come together in peace
and harmony - at least with regard to the technology that is beginning
to break down some of the barriers that divide us.
Wouldn't it be nice if the adoption of Unicode could have that effect?
Well, it may not be the harbinger of world peace, but it does have the
potential for us to be able to better communicate with people of different
nations - and it certainly could open new markets for Omnis Studio and
the applications we write with it!
A Brief History of Written Communication
While we share the ability to communicate vocally and visually with many
of our vertebrate brethren, we humans appear to be unique in the evolution
of a written form of communication. This was developed over a long time
- and long before we ever had computers. The development of writing systems
is just one example of the creativity and diversity of human thought.
We can imagine that the first form of "written" communication
was something like the time-honored tradition of using small rocks, twigs,
bundles of grass and scratches in the dirt to represent prominent features
of the terrain, herds of game animals or groups of "enemies"
and a plan of action. ("You go around this way, we'll go around that
way and we'll have them cornered...") Of course, we must
imagine this because the chance of finding a "fossilized" example
of such early communication - and recognizing it as such - is extremely
remote after tens or even hundreds of thousands of years. Yet it seems
reasonable that we began communicating like this.
Eventually, we learned to dispense with all of the props and just use
images scratched in the dirt. We developed standard representations for
those things for which we once used the physical "models".
As we spread out in waves of migration from Africa, we diverged in many
ways besides geographically. Someone somewhere got the idea to begin leaving
more permanent "writings" on the rock walls of canyons and caves.
Perhaps there were important meanings to these carved petroglyphs and
paintings or perhaps they were just expressions of our innate urge to
draw graffiti and leave our personal mark on the world. Whatever the reason
for their creation, many show signs of an evolving counting system and
standardization (on a local level) of a symbol system.
Once we settled into more permanent villages and towns, there came to
be more reasons for us to keep records and to write down transactions
and stories. There were also reasons to make these writings more portable.
Various writing media and implements emerged - and often the symbols used
to form the local standard system were in part determined by the means
used to write down the symbols. Cuneiform symbols were very much related
to the use of clay tablets and stylus writing implements. Sheets of papyrus
or simple paper and reed brushes or quill pens also influenced the symbolic
forms we devised. But more important were the symbolic units that we chose
to use in our many locales. The invention of printing (only recently)
further led to the standardization of written forms.
Some cultures developed writing systems with sets of symbols that represent
ideas or that use simplified pictures of things while others chose to
use symbols that represent sounds - either individual consonants and/or
vowels or entire syllables. While there was a fair amount or regional
borrowing and copying of symbols, geographic and cultural isolation over
long periods of time have lead to an amazingly diverse set of symbols
when viewed in the whole. Much later, anthropologists located many languages
that did not have a written form and symbol systems were developed to
at least transcribe the strings of sounds made by the speakers of those
languages.
But it is not just words that we symbolize. There have been numerous
symbol systems devised for numbering systems, mathematics, various branches
of scientific and engineering endeavor, music and rhythmic notation and
other fields of human thought. We have been very busy being creative over
the past dozen millennia or so!
What Exactly Is Unicode?
Technically speaking, Unicode itself is simply a concept or a "standard",
like SQL. It is an attempt to represent all known forms of written communication
(past, present and even imaginary in some cases) with a single coding
standard - translating each possible written symbol or symbolic element
used in textual and graphical human communication to a unique number which
can then be easily stored, transmitted and otherwise manipulated by computers
and software that subscribe to this standard. This allows us to deal with
text in any combination of languages within a single document - or database
- without confusion or ambiguity. No small task, given the diversity of
the symbolic characters that we have learned to commit to paper (and other
media) over the years!
The difficulty in attaining this goal is that a number of earlier standards
have already been established in various regions around the world for
working with the local character set on the less capable computers of
the past. Now that computers are much faster, can work with more complex
data values and have vastly more memory than decades ago when those local
standards were first established, it is a good time to revamp the system.
But one obstacle that had to be overcome was how to accommodate all
of the existing standards, as well as to include ancient and marginalized
(or even vanishing) writing systems, in the least disruptive way.
So the Unicode standard is actually a compromise in a number of ways,
with a bit of built-in redundancy forced on it by legacy systems. One
of those compromises deals with characters that are a composite of multiple
glyph elements. To use the Latin symbol system as an example, there are
a small number of basic characters. But these also have upper and lower
case versions. And in many languages that use this basic set, one or more
diacritical marks (accents and other modifying symbols) may be used with
a given symbol to create a new symbol. In many local standards, both the
composite symbol and the individual elements used to build it
are in the local character set. This becomes an even greater challenge
when dealing with logographic and ideographic characters.
But the Unicode standard has been devised to accommodate all of these
characters - and to provide rules and techniques for constructing, deconstructing
and equating composite symbols and their components.
Unicode Fonts
A "Unicode Font" is a font that follows the Unicode encoding
standards to identify character glyphs. Such a font also contains rules
for constructing valid composite character sequences from elemental symbols.
Both TrueType and OpenType fonts support Unicode and use Unicode code
points to map the glyphs they contain.
Only a handful of Unicode fonts actually attempt to contain glyphs for
all of the possible character positions, though. Most support
the basic ASCII set of characters and then one or more sets of glyphs
for a related group of language families or special uses (scientific or
mathematical symbols, dingbats, etc.). This is reasonable when we consider
how much information must be included within the font for holding the
rules regarding composition and decomposition of its characters (among
other rules) - and the amount of RAM that would be required to hold all
of that information when the font is in use.
While we have fonts that contain glyphs associated with specific Unicode
values, those fonts must also contain methods for dealing with composite
glyph duplication. Some more thought had to be given to the Unicode standard
to handle this problem.
Character Normalization
In the database world, we are familiar with the concept of normalization.
To us, this is the process of designing information structures to remove
ambiguity and redundancy to enhance the storage and retrieval of information.
The Unicode techniques for character normalization serve a similar
purpose - and they are a key part of using Unicode with a database and/or
database application.
The idea is to bring each composite character into a normal form for
storage, sorting and other purposes, when there may be a number of ways
of representing that character. In the extreme case, a character may be
a composite of a number of elements - and many subsets of those elements
could form valid composite characters on their own. So the composite character
might have been created using just the elements, a combination of elementals
and simpler composite characters, or it might have been entered using
the one Unicode value for the composite itself.
For example, the 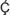 character ("Latin capital letter C with cedilla and acute" -
character number U+1E08) can be composed in a number of ways:
character ("Latin capital letter C with cedilla and acute" -
character number U+1E08) can be composed in a number of ways:
We can simply use the Unicode character number (U+1E08) of its pre-composed
form
We can use the capital C (U+0043) overlaid by the "combining cedilla"
(U+0327) and then by the "combining acute accent" (U+0301)
We can use the capital C overlaid by the "combining acute accent"
and then by the "combining cedilla" (order counts)
We can use the pre-composed C with cedilla (U+00C7) overlaid by the acute
accent
We can use the pre-composed C with acute (U+0106) overlaid by the cedilla
All of these represent the same character, but they are stored and manipulated
differently. Normalization brings any one of these combinations into a
standard form. But what should that standard be?
There are two schools of thought: decomposition and composition. Character
composition is the process of combining simpler characters into fewer
precomposed characters. Decomposition is the opposite process, breaking
precomposed characters back into their component pieces.
Decomposition (NFD normalization) is the simpler of the two techniques.
Using that technique, any composite character is broken into its individual
elements, which are sequenced according to internal rules. This leaves
us with a standard form for the character, but potentially many pieces
to keep track of.
Composition (NFC normalization) first invokes decomposition (just in
case there is a mix of basic and pre-composed elements in the sequence
for a character) and then re-composes the character sequence into a single
pre-composed character (with the elements being applied in a specific
standard order). This reduces the number of characters we need to store
and manipulate, but the process could potentially create a different
character than the original in some rare cases.
The rules for these processes are included within a Unicode font. Applications
that a Unicode compatible understand how to apply those rules and invoke
those processes.
The Unicode Version of Omnis Studio
Omnis Studio internally uses the broadest Unicode standard for representing
characters: UTF-32. This is a fixed-width 32-bit format that can accommodate
any Unicode character code. It uses the UTF-8 standard for most operations.
This is a variable width encoding of 1 to 4 (8-bit) bytes that can also
represent any Unicode character - the standard used by most operating
systems, web browsers and fonts. UTF-32 is just more efficient for internal
operations because it is fixed width, so every character is the same "size".
When we paste values from the clipboard, Omnis Studio automatically applies
NFC normalization to the string being pasted. This reduces the number
of character codes within the string and makes data entry more intuitive
for the user. If uncomposed (deconstructed or semi-constructed) composite
characters exist within a string, additional keystrokes would be required
to move through the character using the arrow keys, for example. Also,
the insertion point would become increasingly de-coupled from the visual
character positions the more deconstructed characters there are in the
string. It is highly recommended that we use this same normalization for
pre-processing strings before performing operations like sorting or comparisons.
Users may still enter character sequences to build composite characters,
so we should perform normalization for consistency.
And so Omnis Studio provides us with both nfd() and nfc()
functions to perform normalization operations. Each function accepts a
single parameter, which is the string to be normalized.
To observe the difference between a pre-composed character and a composite
character sequence, we can perform a simple experiment:
- In the Unicode version of Omnis Studio, create a new library and then
create a new window class within that library.
- Create two National variables named original and normalized.
- Place fields for these variables on the window class.
- Then place a pushbutton field on the window class and put this code
into its $event method:
On evClick
Calculate original as nfd(original) ;; deconstruct the
original
Calculate normalized as nfc(original) ;; construct the
string from deconstructed elements
Redraw
OK message {[len(original)]//[len(normalized)]}
Now find a Unicode character viewing application (I am using the Character
Palette of the Font Viewer within TextEdit on Mac
OS X).
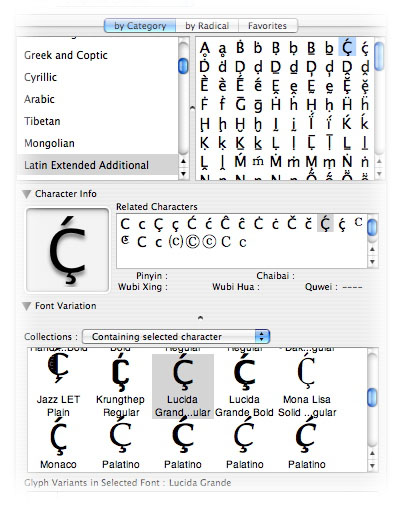
Locate an obvious composite character, copy it to the clipboard (which may
require applying it to a document first) and then paste it into the field
for the original variable. Now click the pushbutton.
When I paste in
and then click the pushbutton, the result I see in the OK message
is that the deconstructed value in original has a length of 3,
while the normalized value in normalized has a length of 1. I
also notice that it requires 3 uses of the arrow key to move the insertion
point in front of this character if it is at the end of the string.
For more incentive to normalize strings in entry fields using nfc(),
I clicked behind the character in original and pressed the left arrow
key only once. I then began typing. The rightmost character that I typed
displayed the acute accent, while the original C-with-all-the-trimmings
lost the acute accent. So the "combining acute" gets
applied to whatever base character precedes it.
Fortunately, Omnis Studio performs the NFC normalization for us on pasting
(which is why we used nfd() to decompose the string in our experiment),
but performing this operation on strings imported by other means - or
retrieved from existing database records - is good insurance. Also, the
automatic NFC normalization is NOT performed when using remote
forms and the nfc() function is NOT available in client-side
methods. We must perform such operations in server-side methods when using
the Omnis Studio web technologies.
Ultimately, future versions of Omnis Studio may well be Unicode-compatible
by default. But for now we must use a separate version. Libraries converted
to the Unicode version of Omnis Studio are not useable by the
non-Unicode version - and there is no reverse conversion. So
if you want to create a Unicode version of one of your libraries, make
sure that you are converting a copy of that library and not
the original (unless you have no desire to have a non-Unicode version
any more).
Until Next Time
There is more to tell about the Unicode version of Omnis Studio, but
it will have to wait for another issue of Omnis Tech News. I hope that
this article has been at least interesting, if not useful, to you. If
you are in the business of creating applications for sale, or if you create
applications for in-house use either for a company with international
branches or for an entity that needs to handle data in multiple languages,
you really should begin experimenting with, or simply using, the Unicode
version. The world awaits...
|  Please logon or create a free account to download this file.
Please logon or create a free account to download this file.






