Omnis Technical Note TNSQ0028 August 2010
Omnis Character Mapping Explained
for Omnis Studio 5.0.1 and later
by Gary Ashford
Introduction
In this Technote, we attempt to explain the processes used to convert
and map Omnis character data when written to and read from an arbitrary
database and to illustrate how the various properties introduced in Studio
5 are used. The intended audience is developers porting non-Unicode applications
to Studio 5 or who need to access data from non-Unicode databases. For
any new applications written using Studio 5, we recommend that DAMs should
be used in the default "Unicode mode" ($unicode=kTrue).
Please note that "character mapping" can only be performed when the session object is operating in non-Unicode mode; since character maps apply only to 8-bit data; providing conversion between various ANSI code pages. When the session object is operating in Unicode mode, the conversion to and from the Unicode encoding expected by the database is carried out automatically by the DAM.
Omnis Character Mapping
Historically, Omnis supports three types of character mapping; using the
native character set, the Omnis character set and custom mapping tables
(implemented using .in and .out files), described as follows:
- The Omnis Character Set option causes character data to be passed to and from the DAM in the internal Omnis character set.
- The Native API Character Set option causes character data to be passed to and from the DAM in the native character set for the platform in question. For example, on Windows this means that data is exchanged between Omnis and the DAM in the ANSI character set. If you are using National characters (characters with a value greater than 127), then this option may be more appropriate for some DAMS, especially if the data you store in the database needs to be accessible to applications other than Omnis. To use this option, you need to understand the character set used by the database server. If the character set is neither the Omnis character set or the native API characters set, then you will need to use a character mapping table to handle national characters... Note that when using a character mapping table, you should select the Omnis Character Set option.
Thus, there is provision for developers who want to write cross platform applications whose data is used exclusively by Omnis and for developers who need their data to be compliant with external applications and specific database character sets.
On the Linux platform it should be noted that the native character set is ISO8859-P1 (Latin 1) is a subset of the Windows CP1252 (or "ANSI") character set. ISO8859-P1 character values in the range 0x80 to 0x9F are not defined/displayable for ISO8859-P1. If an application is to be cross-platform between Windows, Mac and Linux; and the destination character set is ISO8859, then CP1252 characters in the range 0x80 to 0x9F should be avoided or otherwise mapped to different character codes. These include the Euro currency symbol, hooked f, trademark symbol and oe ligature characters for example.
Character Mapping Diagram
The following (simplified) diagram illustrates the processes involved
in converting Omnis character data during insertion into and retrieval
from an external database.
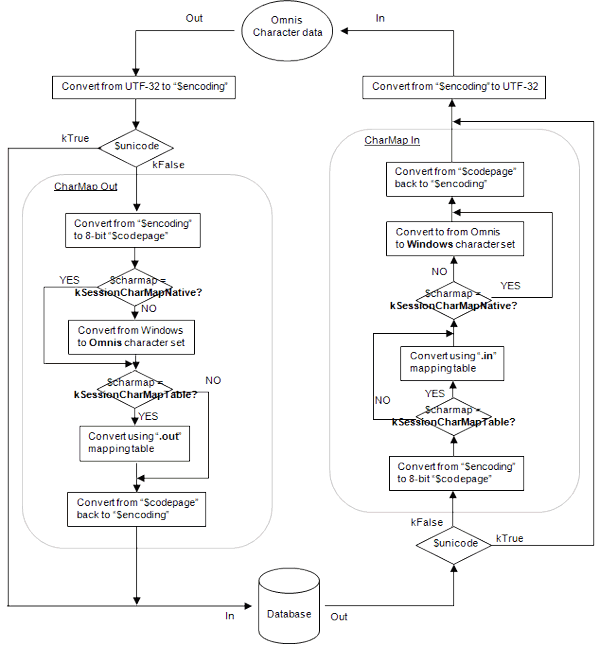
Omnis Studio 5.0: Functional flowchart illustrating input and output character
mapping
From the above diagram, it is possible to infer the following:
- When a session object is operating in Unicode mode
($unicode = kTrue), the only conversion which takes place is conversion
to and from the database encoding; i.e. conversion from the Omnis UTF32
encoding to "$encoding" upon insertion of data and conversion from "$encoding"
to UTF32 upon reading data.
As of Studio 5.0.1, $encoding is a read-only property and is hard-coded according to the value required by the database/client API being used. For Oracle for example; this is set to kSessionEncodingUtf16 whereas for MySQL, it is set to kSessionEncodingUtf8. - 8-bit character mapping requires that character data
is first converted to the specified 8-bit ANSI codepage. After any character
mapping has been performed, the data must then be converted back to
the encoding expected by the client API.
The $codepage property is used to specify the codepage required and accepts any of the following constant values (see Catalog/F9->Unicode types):
kUniTypeAnsiArabic
kUniTypeAnsiBaltic
kUniTypeAnsiCentralEuropean
kUniTypeAnsiCryllic,
kUniTypeAnsiGreek
kUniTypeAnsiHebrew
kUniTypeAnsiLatin1
kUniTypeAnsiThai
kUniTypeAnsiTurkish,
kUniTypeAnsiVietnamese
kUniTypeISO8859_1 - kUniTypeISO8859_16
This means that the DAM will attempt to find any Unicode characters encountered within the specified codepage. Any Unicode characters not catered for by the codepage will be mapped to a "." (0x2E) character. When fetching and converting from these codepages, the DAM assumes that fetched data will consist of characters from the specified codepage. Any incoming 8-bit characters that are not part of the code page will be mapped to a "."
In addition, kUniTypeNativeCharacters can be assigned to $codepage. When this value is specified, the DAM uses an identity mapping: Outgoing Unicode code points are interpreted directly "as" 8-bit character codes and vice-versa. Using this codepage, any Unicode characters (>0xFF) are converted to a "."
Referring to the diagram, the "net" effect of kSessionCharMapNative appears to be conversion from $encoding to $codepage, then back again. Wouldn't it be more efficient to simply skip character mapping in this case? To use an example: conversion from UTF-16 to kUniTypeAnsiLatin1 results in characters not present in the Latin1 codepage being eliminated from the data (replaced by "."s). When converted back to UTF-16, this ensures that the database never "sees" characters which may be incompatible with its character set, thus avoiding any potential insertion errors. (Unicode DAMs must still pass data using the API encoding even when the target database only supports non-Unicode).
- Once converted to 8-bit data, the old (pre-Studio
5) character mapping rules are applied.
That is; if $charmap is set to kSessionCharMapOmnis or kSessionCharMapTable, outgoing data is converted to the Omnis character set. (On the Mac this step is skipped, as data is assumed to be already in the Omnis character set). If $charmap is set to kSessionCharMapNative, conversion is also skipped.
If $charmap is set to kSessionCharMapTable, the custom character map is then applied to the data. (Custom character maps assume that the supplied data will be in the Omnis character set).
Oracle users. It may be of interest to note that when the Oracle session property: $internalcharmapping is set to kFalse, Windows to Omnis and Omnis to Windows character mapping is disabled even when $charmap=kSessionCharMapOmnis or kSessionCharMapTable. Thus, it can be seen that this property enables custom mapping tables to be applied to native character data if required.
- When data is read from the database, the inverse conversion
process is applied.
Note that when $charmap is set to kSessionCharMapTable, incoming data is assumed to be in the Omnis character set. Omnis character data is converted to the Windows character set after custom mapping has been applied. When $charmap is set to kSessionCharMapNative, no character set conversion is performed.
When reading data, kSessionCharMapOmnis/kSessionCharMapTable implies that data should be converted from the Omnis character set to the Native character set. (Incoming character set conversion is skipped on the Mac platform). When $codepage is set to kUniTypeNativeCharacters, each byte "becomes" the Unicode codepoint for that character.
Omnis to Windows Character Conversion
The following table shows the legacy mappings for all MacRoman extended
characters to a notional Windows character set. This mapping table is
inherited from that used by the old-style DAMs and is of uncertain origin.
It will be noted that certain characters for which there are corresponding
characters in the Windows 1252 character set are not mapped correctly
(shown highlighted); notably the dagger, bullet point and trade mark symbols
as well as certain accented characters. For other MacRoman characters
which legitimately do not exist in the CP1252 character set, unique character
codes have been designated. Character codes are shown in both hex and
decimal format:
MacRoman Character |
MacRoman Character Code |
MacToWin WinToMac |
Windows Character Code |
Corresponding CP1252/ANSI Character |
Ä A diaeresis |
80/128 |
C4/196 |
Ä |
|
Å A
ring |
81/129 |
C5/197 |
Å |
|
| Ç C cedilla | 82/130 |
C7/199 |
Ç |
|
| É E acute | 83/131 |
C9/201 |
É |
|
| Ñ N tilde | 84/132 |
D1/209 |
Ñ |
|
| Ö O diaeresis | 85/133 |
D6/214 |
Ö |
|
| Ü U diaeresis | 86/134 |
DC/220 |
Ü |
|
| á a acute | 87/135 |
E1/225 |
á |
|
| à a grave | 88/136 |
E0/224 |
à |
|
| â a circumflex | 89/137 |
E2/226 |
â |
|
| ä a diaeresis | 8A/138 |
E4/228 |
ä |
|
| ã a tilde | 8B/139 |
E3/227 |
ã |
|
| å a ring | 8C/140 |
E5/229 |
å |
|
| ç c cedilla | 8D/141 |
E7/231 |
ç |
|
| é e acute | 8E/142 |
E9/233 |
é |
|
| è e grave | 8F/143 |
E8/232 |
è |
|
| ê e circumflex | 90/144 |
EA/234 |
ê |
|
| ë e diaeresis | 91/145 |
EB/235 |
ë |
|
| í i acute | 92/146 |
ED/237 |
í |
|
| ì i grave | 93/147 |
EC/236 |
ì |
|
| î i circumflex | 94/148 |
EE/238 |
î |
|
| ï i diaeresis | 95/149 |
EF/239 |
ï |
|
| ñ n tilde | 96/150 |
F1/241 |
ñ |
|
| ó o acute | 97/151 |
F3/243 |
ó |
|
| ò o grave | 98/152 |
F2/242 |
ò |
|
| ô o circumflex | 99/153 |
F4/244 |
ô |
|
| ö o diaeresis | 9A/154 |
F6/246 |
ö |
|
| õ o tilde | 9B/155 |
F5/245 |
õ |
|
| ú u acute | 9C/156 |
FA/250 |
ú |
|
| ù u grave | 9D/157 |
F9/249 |
ù |
|
| û u circumflex | 9E/158 |
FB/251 |
û |
|
| ü u diaeresis | 9F/159 |
FC/252 |
ü |
|
| † dagger | A0/160 |
8A/138 |
Š |
|
| ° degree sign | A1/161 |
B0/176 |
° |
|
| ¢ cent sign | A2/162 |
A2/162 |
¢ |
|
| £ pound sign | A3/163 |
A3/163 |
£ |
|
| § section sign | A4/164 |
A7/167 |
§ |
|
| • bullet | A5/165 |
AF/175 |
¯ |
|
| ¶ pilcrow sign | A6/166 |
B6/182 |
¶ |
|
| ß sz ligature | A7/167 |
DF/223 |
ß |
|
| ® registered sign | A8/168 |
AE/174 |
® |
|
| © copyright sign | A9/169 |
A9/169 |
© |
|
| ™ trademark sign | AA/170 |
81/129 |
not
defined |
|
| ´ acute accent | AB/171 |
B4/180 |
´ |
|
| ¨ diaeresis | AC/172 |
A8/168 |
¨ |
|
| ≠ not equal to | AD/173 |
82/130 |
‚ |
|
| Æ AE ligature | AE/174 |
C6/198 |
Æ |
|
| Ø O slash | AF/175 |
D8/216 |
Ø |
|
| ∞ infinity | B0/176 |
83/131 |
ƒ |
|
| ± plus-minus sign | B1/177 |
B1/177 |
± |
|
| ≤ less than or equal to | B2/178 |
84/132 |
" |
|
| ≥ more than or equal to | B3/179 |
85/133 |
… |
|
| ¥ yen sign | B4/180 |
A5/165 |
¥ |
|
| µ micro sign | B5/181 |
B5/181 |
µ |
|
| ∂ partial differential | B6/182 |
F0/240 |
ð |
|
| Σ n-ary summation | B7/183 |
86/134 |
† |
|
| ∏ n-ary product | B8/184 |
87/135 |
‡ |
|
| π Greek letter pi | B9/185 |
88/136 |
ˆ |
|
| ∫ integral | BA/186 |
89/137 |
‰ |
|
| ª feminine ordinal indicator | BB/187 |
AA/170 |
ª |
|
| º masculine ordinal indicator | BC/188 |
BA/186 |
° |
|
| Ω Greek capital omega | BD/189 |
8B/139 |
‹ |
|
| æ ae ligature | BE/190 |
E6/230 |
æ |
|
| ø o slash | BF/191 |
F8/248 |
ø |
|
| ¿ inverted question mark | C0/192 |
BF/191 |
¿ |
|
| ¡ inverted exclamation mark | C1/193 |
A1/161 |
¡ |
|
| ¬ not sign | C2/194 |
AC/172 |
¬ |
|
| √ square root | C3/195 |
8C/140 |
Π|
|
| ƒ hooked f | C4/196 |
8D/141 |
not
defined |
|
| ≈ almost equal to | C5/197 |
8E/142 |
Ž |
|
C6/198 |
8F/143 |
not
defined |
||
| « double left-pointing angle | C7/199 |
AB/171 |
« |
|
| » double right-pointing angle | C8/200 |
BB/187 |
» |
|
| … horizonal ellipsis | C9/201 |
90/144 |
not
defined |
|
| non-breaking space | CA/202 |
A0/160 |
non-breaking space |
|
| À A grave | CB/203 |
C0/192 |
À |
|
| Ã A tilde | CC/204 |
C3/195 |
à |
|
| Õ O tilde | CD/205 |
D5/213 |
Õ |
|
| ΠOE ligature | CE/206 |
94/148 |
" |
|
| œ oe ligature | CF/207 |
95/149 |
• |
|
| – en dash | D0/208 |
AD/173 |
|
|
| — em dash | D1/209 |
96/150 |
|
|
| “ double left quotation mark | D2/210 |
97/151 |
— |
|
| ” double right quotation mark | D3/211 |
98/152 |
˜ |
|
| ‘ single left quotation mark | D4/212 |
91/145 |
' |
|
| ’ single right quotation mark | D5/213 |
92/146 |
' |
|
| ÷ division sign | D6/214 |
F7/247 |
÷ |
|
| â—Š◊ lozenge | D7/215 |
A4/164 |
¤ |
|
| ÿ y diaeresis | D8/216 |
FF/255 |
ÿ |
|
| Ÿ Y diaeresis | D9/217 |
93/147 |
" |
|
| â„⁄ fraction slash | DA/218 |
A6/166 |
| |
|
| € euro sign | DB/219 |
80/128 |
€ |
|
| ‹ left-pointing angle | DC/220 |
B2/178 |
² |
|
| › right-pointing angle | DD/221 |
B3/179 |
³ |
|
DE/222 |
B7/183 |
· |
||
DF/223 |
B8/184 |
¸ |
||
| ‡ double dagger | E0/224 |
B9/185 |
¹ |
|
| · middle dot | E1/225 |
BC/188 |
¼ |
|
| ‚ single low-9 quotation mark | E2/226 |
BD/189 |
½ |
|
| „ double low-9 quotation mark | E3/227 |
BE/190 |
¾ |
|
| ‰ per mille sign | E4/228 |
C1/193 |
Á |
|
| Â A circumflex | E5/229 |
C2/194 |
 |
|
| Ê E circumflex | E6/230 |
C8/200 |
È |
|
| Á A acute | E7/231 |
CA/202 |
Ê |
|
| Ë E diaeresis | E8/232 |
CB/203 |
Ë |
|
| È E grave | E9/233 |
CC/204 |
Ì |
|
| Í I acute | EA/234 |
CD/205 |
Í |
|
| Î I circumflex | EB/235 |
CE/206 |
Î |
|
| Ï I diaeresis | EC/236 |
CF/207 |
Ï |
|
| Ì I grave | ED/237 |
D0/208 |
Ð |
|
| Ó O acute | EE/238 |
D2/210 |
Ò |
|
| Ô O circumflex | EF/239 |
D3/211 |
Ó |
|
F0/240 |
D4/212 |
Ô |
||
| Ò O grave | F1/241 |
D9/217 |
Ù |
|
| Ú U acute | F2/242 |
DA/218 |
Ú |
|
| Û U circumflex | F3/243 |
DB/219 |
Û |
|
| Ù U grave | F4/244 |
DD/221 |
Ý |
|
F5/245 |
DE/222 |
Þ |
||
| ˆ circumflex accent | F6/246 |
FD/253 |
ý |
|
| ˜ tilde | F7/247 |
FE/254 |
þ |
|
| ¯ macron | F8/248 |
D7/215 |
× |
|
F9/249 |
9B/155 |
› |
||
FA/250 |
9C/156 |
œ |
||
FB/251 |
9D/157 |
not
defined |
||
| ¸ cedilla | FC/252 |
9E/158 |
ž |
|
FD/253 |
9F/159 |
Ÿ |
||
FE/254 |
9A/154 |
š |
||
FF/255 |
99/153 |
™ |
Although not shown here (to avoid duplication), the inverse table maps from the hybrid Windows character set back to the original MacRoman character codes.
This table exposes a potential problem with cross-platform applications using the Omnis character set in that the highlighted characters will not be "cross-platform". They will appear correctly on Mac or on Windows (depending on which platform they were inserted from), but not both. The workaround for this problem has always been to implement custom mapping tables to handle these additional characters if needed.
UTF8 Data
Where the database uses the UTF8 encoding (MySQL and PostgreSQL for example),
this poses an additional problem for DAMs operating in non-Unicode mode.
Specifically; when a byte value greater than 0x7F is read from the database,
should this be treated as a non-Unicode extended character or as the first
byte of a multi-byte UTF8 character? (UTF8 bytes greater than 0x7F are
used to indicate that one or more additional bytes are required to encode
a character. UTF8 characters can use between 1 and 4 bytes)
Problems can ensue if UTF8 byte sequences are read by a DAM operating in non-Unicode mode and treated as individual extended 8-bit characters. This situation should be avoided by ensuring that you do not access the UTF8 database using DAM operating in Unicode mode (thus avoiding the possibility of Unicode characters). If the database already contains a mixture of ANSI extended characters and multi-byte UTF8 characters, your best option is to revert to Unicode mode ($unicode=kTrue) and use the $validateutf8 property instead.
In Studio 5, the $validateutf8 session property forces any fetched character data to be validated using the rules for UTF8 encoding. If the byte (or bytes) of data satisfy the rules for UTF8 encoding, that sequence is taken as a UTF8 character. All characters in the data must satisfy these rules for the data to be treated as UTF8. Otherwise the data is treated as non-Unicode and is converted as described earlier. When $unicode is set to kTrue, any character data written back to the database will be converted to UTF8.
Database Character Conversion
There is one further consideration regarding character conversion; namely
any conversion which may be performed by the database and/or client library
when reading and writing data. Oracle for example has provision for many
non-Unicode as well as Unicode character sets and it is up to the developer
to ensure that the target encoding and character set are compatible with
the database and that the destination data types are suitable (VARCHAR2
versus NVARCHAR2 for example). Where Oracle is concerned, you are responsible
for matching the client character set (specified via the NLS_LANG environment
variable) with the character set being used by the DAM. It is the responsibility
of the Oracle database to convert between the client character set and
the database character set. This is usually possible in all but the most
extreme combinations, although it should be noted that writing Windows
CP1252 character data to an ISO8859-P1 database (NLS_LANG = AMERICAN_AMERICA.WE8ISO8859P1)
for example, will result in the "loss" of character codes in the range
0x80 to 0x9F. (Oracle will convert them to "¿" (0xBF) ).
Conclusions
In Studio 5, it is possible to continue accessing non-Unicode databases
in a largely cross-platform and cross-application manner. Furthermore,
in Studio 5 it is possible to interface with non-Unicode databases using
different 8-bit ANSI codepages; by making use of the $codepage property
in conjunction with the "Native character set". In this manner, you can
map to and from the extended characters in a given codepage.
Alternatively, the "Omnis character set" can be used to store non-Unicode data directly, or Omnis character set data can be translated using custom mapping tables, thus retaining the old non-Unicode DAM behaviour. Studio 5 can automatically port non-Unicode data in UTF8 databases to Unicode by detecting Unicode and non-Unicode byte sequences. Once converted however, care should be taken not to expose non-Unicode applications to Unicode data.
References and Further Reading
The following links may be of interest:

 Facebook
Facebook Github
Github Instagram
Instagram Linkedin
Linkedin Twitter
Twitter Youtube
Youtube Please logon or create a free account to download this file.
Please logon or create a free account to download this file.
